在家庭实验室或小型企业环境中,Proxmox Virtual Environment (PVE) 是一个非常流行的虚拟化平台。随着虚拟机数量的增加,如何有效监控这些系统的运行状态成为一个重要课题。本文将介绍如何搭建一套完整的混合云监控系统,实现对 PVE 宿主机及虚拟机的全方位监控。
项目概述
本项目采用 Prometheus + Grafana + Alertmanager 作为核心监控栈,结合 Frp 内网穿透 技术,构建了一套混合云监控架构:
- 阿里云服务器 :部署监控中心(Prometheus、Grafana、Alertmanager)
- 本地 PVE 环境 :通过 Frp 内网穿透,将监控数据上报到云端
注意!!!本篇共两部分第一部分为手动部署指南,第二部分为一件快速部署
前提条件:
硬件要求
软件环境
阿里云服务器(监控中心):
本地 PVE 环境:
网络要求
阿里云服务器 :需要公网 IP,开放以下端口(端口如果占用自行更改)
本地 PVE 环境 :能够访问公网(用于连接 Frp 服务端)
环境监察脚本
平台:阿里云服务器
# 检查 Docker
docker --version || echo "请先安装 Docker"
# 检查 Docker Compose
docker compose version || docker-compose --version || echo "请先安装 Docker Compose"
# 检查端口占用
netstat -tlnp | grep -E '3000|8006|9090|9093' || echo "端口未被占用"安装 Docker(如未安装)
# 一键安装 Docker
curl -fsSL https://get.docker.com | sh
# 启动 Docker 服务
systemctl start docker
systemctl enable docker
# 安装 Docker Compose(如需要)
curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose架构图
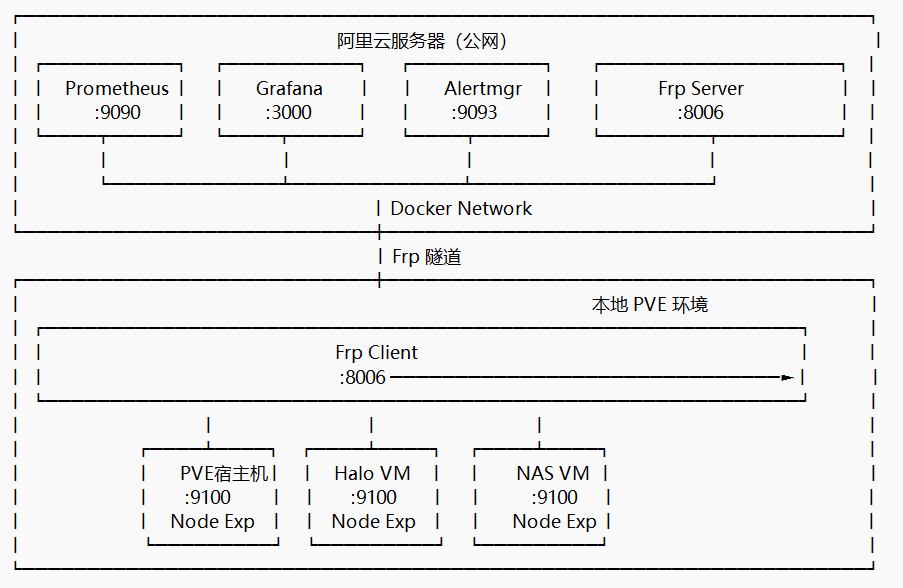
因为我自己也就装了两个虚拟机加上PVE本身所以可监视的就三个部分。
特别注意!!!提前说明(配置修改清单)
一、需要修改 IP 地址的位置
二、需要修改 Grafana 账号密码的位置
三、需要修改的其他配置项
四、快速修改对照表
阿里云服务器配置(步骤 6、7)
本地 PVE 服务器配置(步骤 2)本地 PVE 服务器配置(步骤 2)本地 PVE 服务器配置(步骤 2)本地 PVE 服务器配置(步骤 2)本地 PVE 服务器配置(步骤 2)# frp/frps.toml
auth.token = "your_secure_token_here" # ← 修改为安全密钥
webServer.password = "your_password_here" # ← 修改 Frp 面板密码
# docker-compose.yml
GF_SECURITY_ADMIN_PASSWORD=your_password_here # ← 修改 Grafana 密码本地 PVE 服务器配置(步骤 2)
# /etc/frp/frpc.toml
serverAddr = "your_aliyun_ip" # ← 修改为阿里云公网 IP
auth.token = "your_secure_token_here" # ← 必须与服务端一致
localIP = "192.168.1.38" # ← 修改为 Halo VM 实际 IP
localIP = "192.168.1.3" # ← 修改为 NAS VM 实际 IP五、一键部署脚本自动处理
如果使用 第二部分:一键快速部署 ,脚本会交互式询问以下配置:
请输入阿里云服务器公网IP: # ← 输入阿里云 IP
请输入 Frp 通信密钥 (默认: pve_monitor_2024): # ← 输入 token
请输入 Grafana 管理员密码 (默认: admin123): # ← 输入 Grafana 密码脚本会自动更新配置文件中的对应值。
第一部分:手动部署指南
本部分将详细介绍每个组件的配置和部署过程,适合想深入了解监控系统的读者。
一、核心组件介绍
1. Prometheus - 监控数据采集与存储
Prometheus 是一个开源的监控和告警系统,采用 拉取模式 采集指标数据。
2. Grafana - 可视化监控面板
Grafana 提供了强大的可视化能力,支持多种图表类型。
3. Alertmanager - 告警管理
Alertmanager 负责告警的去重、分组、路由和通知。
4. Frp 内网穿透
Frp 是解决内网监控的关键技术,实现公网访问内网服务。
二、阿里云服务器部署(监控中心)
以下所有操作均在【阿里云服务器】上执行
步骤 1:创建项目目录
mkdir -p /opt/pve-monitoring/{prometheus/alerts,grafana/provisioning/{dashboards,datasources},alertmanager,frp,nginx,scripts}
cd /opt/pve-monitoring步骤 2:配置 Prometheus
创建 prometheus/prometheus.yml :
# =============================================================================
# Prometheus 配置文件
# =============================================================================
# 功能说明:
# Prometheus 是一个开源的监控和告警系统,采用拉取模式采集指标数据
# 本配置定义了数据采集目标、告警规则和全局参数
# =============================================================================
global:
# 数据采集间隔:每 15 秒采集一次指标数据
scrape_interval: 15s
# 告警规则评估间隔:每 15 秒评估一次告警规则
evaluation_interval: 15s
# 外部标签:用于标识监控集群
external_labels:
monitor: 'pve-monitoring'
# 告警管理器配置
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# 告警规则文件路径
rule_files:
- /etc/prometheus/alerts/*.yml
# 数据采集配置
scrape_configs:
# Job 1: Prometheus 自身监控
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
labels:
instance: 'prometheus'
# Job 2: 阿里云服务器监控
- job_name: 'aliyun-server'
static_configs:
- targets: ['node-exporter-aliyun:9100']
labels:
instance: 'aliyun-server'
env: 'production'
# Job 3: PVE 宿主机监控
# 通过 Frp 内网穿透采集,端口 9101
- job_name: 'pve-host'
static_configs:
- targets: ['frps:9101']
labels:
instance: 'pve-host'
env: 'local'
# Job 4: Halo 博客虚拟机监控
# 通过 Frp 映射到 9102 端口
- job_name: 'halo-vm'
static_configs:
- targets: ['frps:9102']
labels:
instance: 'halo-vm'
env: 'local'
service: 'halo'
# Job 5: 飞牛NAS 虚拟机监控
# 通过 Frp 映射到 9103 端口
- job_name: 'nas-vm'
static_configs:
- targets: ['frps:9103']
labels:
instance: 'nas-vm'
env: 'local'
service: 'nas'步骤 3:配置告警规则
创建 prometheus/alerts/server-alerts.yml :
# =============================================================================
# Prometheus 告警规则配置
# =============================================================================
# 功能说明:
# 定义各种监控告警规则,当指标满足条件时触发告警
# Prometheus 会定期评估这些规则,并将触发的告警发送给 Alertmanager
#
# 告警规则结构:
# alert - 告警名称
# expr - PromQL 表达式,定义触发条件
# for - 持续时间,条件满足多久后才触发告警
# labels - 告警标签,用于分类和路由
# annotations - 告警详情,包含摘要和描述信息
# =============================================================================
groups:
- name: server_alerts # 告警规则组名称
rules:
# -------------------------------------------------------------------------
# 告警规则 1:实例宕机检测
# -------------------------------------------------------------------------
# 当目标无法被采集(up == 0)持续 1 分钟,触发告警
# up 指标:1 表示正常,0 表示无法访问
- alert: InstanceDown
expr: up == 0
for: 1m # 持续 1 分钟后触发
labels:
severity: critical # 严重级别:critical(严重)
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minute."
# -------------------------------------------------------------------------
# 告警规则 2:CPU 使用率过高
# -------------------------------------------------------------------------
# 当 CPU 使用率超过 80% 持续 5 分钟,触发告警
# 计算公式:100 - CPU空闲率
- alert: HighCPUUsage
expr: 100 - (avg by(instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 5m
labels:
severity: warning # 严重级别:warning(警告)
annotations:
summary: "High CPU usage on {{ $labels.instance }}"
description: "CPU usage is {{ $value }}% on {{ $labels.instance }}"
# -------------------------------------------------------------------------
# 告警规则 3:内存使用率过高
# -------------------------------------------------------------------------
# 当内存使用率超过 85% 持续 5 分钟,触发告警
# 计算公式:(总内存 - 可用内存) / 总内存 * 100
- alert: HighMemoryUsage
expr: (1 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes)) * 100 > 85
for: 5m
labels:
severity: warning
annotations:
summary: "High memory usage on {{ $labels.instance }}"
description: "Memory usage is {{ $value }}% on {{ $labels.instance }}"
# -------------------------------------------------------------------------
# 告警规则 4:磁盘空间不足(警告级别)
# -------------------------------------------------------------------------
# 当磁盘剩余空间低于 15% 持续 5 分钟,触发警告
# 排除 tmpfs 和 overlay 文件系统(Docker 临时文件系统)
- alert: DiskSpaceLow
expr: (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"}) * 100 < 15
for: 5m
labels:
severity: warning
annotations:
summary: "Low disk space on {{ $labels.instance }}"
description: "Disk {{ $labels.mountpoint }} has only {{ $value }}% space left on {{ $labels.instance }}"
# -------------------------------------------------------------------------
# 告警规则 5:磁盘空间严重不足(严重级别)
# -------------------------------------------------------------------------
# 当磁盘剩余空间低于 5% 持续 1 分钟,触发严重告警
- alert: DiskSpaceCritical
expr: (node_filesystem_avail_bytes{fstype!~"tmpfs|overlay"} / node_filesystem_size_bytes{fstype!~"tmpfs|overlay"}) * 100 < 5
for: 1m
labels:
severity: critical
annotations:
summary: "Critical disk space on {{ $labels.instance }}"
description: "Disk {{ $labels.mountpoint }} has only {{ $value }}% space left on {{ $labels.instance }}"
# -------------------------------------------------------------------------
# 告警规则 6:网络流量异常
# -------------------------------------------------------------------------
# 当网络接收速率超过 100MB/s 持续 5 分钟,触发告警
# 排除回环接口、虚拟网卡和 Docker 网卡
- alert: HighNetworkTraffic
expr: rate(node_network_receive_bytes_total{device!~"lo|veth.*|docker.*"}[5m]) > 100000000
for: 5m
labels:
severity: warning
annotations:
summary: "High network traffic on {{ $labels.instance }}"
description: "Network receive rate is {{ $value | humanize }}B/s on {{ $labels.instance }}"步骤 4:配置 Alertmanager
创建 alertmanager/alertmanager.yml :
步骤 5:配置 Grafana 数据源步骤 5:配置 Grafana 数据源步骤 5:配置 Grafana 数据源步骤 5:配置 Grafana 数据源# =============================================================================
# Alertmanager 配置文件
# =============================================================================
# 功能说明:
# Alertmanager 是 Prometheus 的告警管理组件
# 负责接收 Prometheus 发送的告警,进行去重、分组、路由和发送通知
#
# 主要功能:
# 1. 告警去重:避免重复告警
# 2. 告警分组:将相关告警合并发送
# 3. 告警路由:根据标签将告警发送到不同的接收者
# 4. 告警抑制:当某些告警触发时,抑制其他告警
# =============================================================================
# -----------------------------------------------------------------------------
# 全局配置
# -----------------------------------------------------------------------------
global:
# 告警恢复超时时间:如果告警在 5 分钟内没有更新,则认为已恢复
resolve_timeout: 5m
# SMTP 邮件服务器配置(用于发送邮件告警)
smtp_smarthost: 'smtp.example.com:587' # SMTP 服务器地址和端口
smtp_from: 'alertmanager@example.com' # 发件人邮箱
smtp_auth_username: 'alertmanager@example.com' # SMTP 认证用户名
smtp_auth_password: 'your_smtp_password' # SMTP 认证密码
# -----------------------------------------------------------------------------
# 路由配置
# -----------------------------------------------------------------------------
# 定义告警如何被分组和路由到不同的接收者
# -----------------------------------------------------------------------------
route:
# 分组依据:按告警名称和严重级别分组
# 相同告警名称和严重级别的告警会被合并发送
group_by: ['alertname', 'severity']
# 分组等待时间:等待 30 秒收集同组告警后再发送
# 避免频繁发送告警
group_wait: 30s
# 分组间隔:同一组告警的发送间隔
group_interval: 5m
# 重复告警间隔:同一告警的重复发送间隔
repeat_interval: 4h
# 默认接收者:未匹配到子路由的告警发送到此接收者
receiver: 'default-receiver'
# 子路由配置:根据标签匹配不同的接收者
routes:
# 严重告警路由
- match:
severity: critical
receiver: 'critical-receiver'
# 警告级别告警路由
- match:
severity: warning
receiver: 'warning-receiver'
# -----------------------------------------------------------------------------
# 接收者配置
# -----------------------------------------------------------------------------
# 定义告警通知的接收方式(邮件、Webhook、钉钉、微信等)
# -----------------------------------------------------------------------------
receivers:
# 默认接收者:通过 Webhook 发送告警
- name: 'default-receiver'
webhook_configs:
- url: 'http://alertmanager-webhook:5001/webhook'
send_resolved: true # 发送恢复通知
# 严重告警接收者:同时发送到钉钉、微信和邮件
- name: 'critical-receiver'
webhook_configs:
# 钉钉 Webhook
- url: 'http://alertmanager-webhook:5001/webhook/dingtalk'
send_resolved: true
# 企业微信 Webhook
- url: 'http://alertmanager-webhook:5001/webhook/wechat'
send_resolved: true
# 邮件通知
email_configs:
- to: 'admin@example.com'
send_resolved: true
# 警告级别接收者:仅发送到钉钉
- name: 'warning-receiver'
webhook_configs:
- url: 'http://alertmanager-webhook:5001/webhook/dingtalk'
send_resolved: true
# -----------------------------------------------------------------------------
# 抑制规则配置
# -----------------------------------------------------------------------------
# 当某些告警触发时,抑制其他告警的发送
# 避免告警风暴,减少干扰
# -----------------------------------------------------------------------------
inhibit_rules:
# 当严重告警触发时,抑制同一实例的警告级别告警
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'instance'] # 相同告警名称和实例才抑制步骤 5:配置 Grafana 数据源
创建 grafana/provisioning/datasources/datasources.yml :
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
isDefault: true
editable: false
jsonData:
timeInterval: "15s" # 数据采集间隔,与 Prometheus 配置保持一致
httpMethod: "POST" # 使用 POST 方法查询,性能更好步骤 6:配置 Frp 服务端
创建 frp/frps.toml :
# =============================================================================
# Frp Server 配置文件 - 内网穿透服务端
# =============================================================================
# 功能说明:
# 此配置文件运行在阿里云服务器(公网端),作为 Frp 服务端
# 负责接收本地 PVE 的 Frp 客户端连接,并将内网服务暴露到公网
#
# 工作原理:
# 本地 PVE (frpc) -----> 阿里云 -----> 公网访问
# 内网服务通过 Frp 隧道映射到阿里云的端口,实现内网穿透
# =============================================================================
# -----------------------------------------------------------------------------
# 基础配置
# -----------------------------------------------------------------------------
# 绑定地址:0.0.0.0 表示监听所有网卡,允许外部连接
bindAddr = "0.0.0.0"
# 绑定端口:客户端需要连接此端口与服务端建立隧道
bindPort = 8006
# -----------------------------------------------------------------------------
# 认证配置
# -----------------------------------------------------------------------------
# 认证方式:使用 token 令牌认证
# 客户端必须配置相同的 token 才能连接
auth.method = "token"
# 认证令牌:请修改为安全的密钥
auth.token = "your_secure_token_here"
# -----------------------------------------------------------------------------
# Web 管理面板配置
# -----------------------------------------------------------------------------
# 管理面板监听地址
webServer.addr = "0.0.0.0"
# 管理面板端口:7500
# 访问 http://阿里云IP:7500 可以查看 Frp 连接状态
webServer.port = 7500
# 管理面板登录用户名
webServer.user = "admin"
# 管理面板登录密码(建议修改)
webServer.password = "your_password_here"
# -----------------------------------------------------------------------------
# 日志配置
# -----------------------------------------------------------------------------
# 日志文件路径
log.to = "/var/log/frps.log"
# 日志级别:trace, debug, info, warn, error
log.level = "info"
# 日志保留天数
log.maxDays = 7步骤 7:创建 Docker Compose 文件
创建 docker-compose.yml :
# =============================================================================
# Docker Compose 配置文件 - PVE 混合云监控系统
# =============================================================================
# 功能说明:
# 使用 Docker Compose 编排部署以下服务:
# - Prometheus: 时序数据库,用于存储和查询监控指标
# - Alertmanager: 告警管理器,处理来自 Prometheus 的告警
# - Grafana: 可视化面板,展示监控数据
# - Node Exporter: 系统指标采集器,采集阿里云服务器指标
# - Frp Server: 内网穿透服务端,接收本地 PVE 的连接
# =============================================================================
version: '3.8'
services:
# ---------------------------------------------------------------------------
# Prometheus - 核心监控数据存储和查询引擎
# ---------------------------------------------------------------------------
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./prometheus/alerts:/etc/prometheus/alerts:ro
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.enable-lifecycle' # 启用热重载配置
- '--web.enable-admin-api' # 启用管理 API
networks:
- monitoring
# ---------------------------------------------------------------------------
# Alertmanager - 告警管理器
# ---------------------------------------------------------------------------
alertmanager:
image: prom/alertmanager:latest
container_name: alertmanager
restart: always
ports:
- "9093:9093"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro
- alertmanager_data:/alertmanager
networks:
- monitoring
# ---------------------------------------------------------------------------
# Grafana - 监控数据可视化面板
# ---------------------------------------------------------------------------
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: always
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_USER=admin
- GF_SECURITY_ADMIN_PASSWORD=your_password_here
- GF_USERS_ALLOW_SIGN_UP=false
- GF_SERVER_ROOT_URL=http://monitor.yourdomain.com
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning:ro
depends_on:
- prometheus
networks:
- monitoring
# ---------------------------------------------------------------------------
# Node Exporter - 阿里云服务器指标采集器
# ---------------------------------------------------------------------------
node-exporter-aliyun:
image: prom/node-exporter:latest
container_name: node-exporter-aliyun
restart: always
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|etc|var)($$|/)'
networks:
- monitoring
# ---------------------------------------------------------------------------
# Frp Server - 内网穿透服务端
# ---------------------------------------------------------------------------
# 端口说明:
# 8006 - Frp 通信端口(客户端连接此端口)
# 7500 - Frp 管理面板端口
# 9101 - PVE 宿主机 Node Exporter
# 9102 - Halo 虚拟机 Node Exporter
# 9103 - NAS 虚拟机 Node Exporter
# ---------------------------------------------------------------------------
frps:
image: snowdreamtech/frps:latest
container_name: frps
restart: always
ports:
- "8006:8006" # Frp 主通信端口
- "7500:7500" # Frp Web 管理面板
- "9101:9101" # PVE 宿主机 Node Exporter
- "9102:9102" # Halo 虚拟机 Node Exporter
- "9103:9103" # NAS 虚拟机 Node Exporter
volumes:
- ./frp/frps.toml:/etc/frp/frps.toml:ro
networks:
- monitoring
volumes:
prometheus_data:
alertmanager_data:
grafana_data:
networks:
monitoring:
driver: bridge步骤 8:启动服务
# 启动所有服务
docker compose up -d
# 查看服务状态
docker compose ps
# 查看日志
docker compose logs -f步骤 9:验证部署
步骤 10:导入 Grafana 仪表板
平台:浏览器(访问 Grafana Web 界面)
1. 登录 Grafana(默认账号:admin,密码:你设置的密码)
2. 左侧菜单选择 Dashboards → Import
3. 输入模板 ID: 1860
4. 点击 Load ,选择数据源 Prometheus
5. 点击 Import 完成导入
三、本地 PVE 环境部署
以下所有操作均在【本地 PVE 服务器】上执行
步骤 1:安装 Node Exporter
# 下载 Node Exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-amd64.tar.gz
# 解压
tar xzf node_exporter-1.7.0.linux-amd64.tar.gz
mv node_exporter-1.7.0.linux-amd64/node_exporter /usr/local/bin/
# 创建 systemd 服务
cat > /etc/systemd/system/node_exporter.service << EOF
[Unit]
Description=Node Exporter
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/bin/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动服务
systemctl daemon-reload
systemctl start node_exporter
systemctl enable node_exporter
# 验证
curl http://localhost:9100/metrics步骤 2:配置 Frp 客户端
创建 /etc/frp/frpc.toml :
# =============================================================================
# Frp Client 配置文件 - 内网穿透客户端
# =============================================================================
# 功能说明:
# 此配置文件运行在本地 PVE 服务器,作为 Frp 客户端
# 负责连接阿里云的 Frp 服务端,将本地服务暴露到公网
#
# 工作原理:
# 本地服务 -> frpc -> [Frp隧道] -> frps(阿里云) -> 公网访问
# 内网服务通过 Frp 隧道映射到阿里云的端口
# =============================================================================
# -----------------------------------------------------------------------------
# 服务端连接配置
# -----------------------------------------------------------------------------
# 阿里云服务器公网 IP
serverAddr = "your_aliyun_ip"
# Frp 服务端端口(与服务端配置保持一致)
serverPort = 8006
# -----------------------------------------------------------------------------
# 认证配置
# -----------------------------------------------------------------------------
# 认证方式:必须与服务端保持一致
auth.method = "token"
# 认证令牌(必须与服务端配置相同)
auth.token = "your_secure_token_here"
# -----------------------------------------------------------------------------
# 代理配置
# -----------------------------------------------------------------------------
# 每个代理定义一个本地服务到公网的映射
#
# 参数说明:
# name - 代理名称,在服务端管理面板中显示
# type - 协议类型:tcp, udp, http, https 等
# localIP - 本地服务的 IP 地址
# localPort - 本地服务的端口
# remotePort - 映射到服务端的公网端口
# -----------------------------------------------------------------------------
# 代理1:PVE 宿主机 Node Exporter 监控指标
# 将 PVE 宿主机的 Node Exporter 暴露到公网,供 Prometheus 采集监控数据
[[proxies]]
name = "pve-node-exporter"
type = "tcp"
localIP = "127.0.0.1" # PVE 宿主机本地地址
localPort = 9100 # Node Exporter 默认端口
remotePort = 9101 # 映射到阿里云的 9101 端口
# 代理2:Halo 博客虚拟机 Node Exporter
# 将 Halo 虚拟机的监控指标暴露到公网
[[proxies]]
name = "halo-node-exporter"
type = "tcp"
localIP = "192.168.1.38" # Halo 虚拟机的内网 IP
localPort = 9100 # Node Exporter 默认端口
remotePort = 9102 # 映射到阿里云的 9102 端口
# 代理3:飞牛NAS 虚拟机 Node Exporter
# 将 NAS 虚拟机的监控指标暴露到公网
[[proxies]]
name = "nas-node-exporter"
type = "tcp"
localIP = "192.168.1.3" # 飞牛NAS 虚拟机的内网 IP
localPort = 9100 # Node Exporter 默认端口
remotePort = 9103 # 映射到阿里云的 9103 端口
# -----------------------------------------------------------------------------
# 日志配置
# -----------------------------------------------------------------------------
# 日志文件路径
log.to = "/var/log/frpc.log"
# 日志级别:trace, debug, info, warn, error
log.level = "info"
# 日志保留天数
log.maxDays = 7步骤 3:启动 Frp 客户端
# 下载 Frp
wget https://github.com/fatedier/frp/releases/download/v0.52.0/frp_0.52.0_linux_amd64.tar.gz
tar xzf frp_0.52.0_linux_amd64.tar.gz
mv frp_0.52.0_linux_amd64/frpc /usr/local/bin/
# 创建 systemd 服务
cat > /etc/systemd/system/frpc.service << EOF
[Unit]
Description=Frp Client
After=network.target
[Service]
Type=simple
ExecStart=/usr/local/bin/frpc -c /etc/frp/frpc.toml
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动服务
systemctl daemon-reload
systemctl start frpc
systemctl enable frpc四、配置告警通知(可选) 平台:阿里云服务器 (修改 webhook 服务配置)
配置钉钉机器人
1. 在钉钉群中添加自定义机器人
2. 获取 Webhook 地址
3. 修改 scripts/alert-webhook.py 中的 DINGTALK_WEBHOOK
配置企业微信机器人
1. 在企业微信群中添加群机器人
2. 获取 Webhook 地址
3. 修改 scripts/alert-webhook.py 中的 WECHAT_WEBHOOK
第二部分:一键快速部署
本部分适合快速搭建监控系统的读者,只需运行脚本即可完成部署。
一、项目文件结构
点击链接下载压缩包PVE porject.zip
二、快速部署步骤
步骤1:阿里云服务器部署(监控中心)
1.1 上传项目文件
平台:阿里云服务器
将项目文件夹上传到阿里云服务器任意目录
1.2 一键配置并启动
# 进入项目目录
cd /opt/pve-monitoring
# 赋予执行权限
chmod +x deploy.sh
chmod +x scripts/*.sh
# 执行一键部署
./deploy.sh1.3 部署脚本交互内容
脚本会询问以下配置(按提示输入即可)
1.4 验证服务启动
# 查看服务状态
docker compose ps
# 访问地址(替换为你的实际IP)
Grafana: http://你的阿里云IP:3000
Prometheus: http://你的阿里云IP:9090
Alertmanager: http://你的阿里云IP:9093
Frp管理面板: http://你的阿里云IP:7500步骤2:本地PVE环境部署(被监控端)
平台:PVE本地服务器
2.1 上传scripts文件夹到PVE服务器
# 上传scripts文件夹到PVE服务器
cd /opt/pve-monitoring/scripts
# 赋予执行权限
chmod +x *.sh
# 一键安装Node Exporter
./install-node-exporter.sh2.2 配置Frp客户端
# 复制frpc配置模板
cp ../frp/frpc.toml /etc/frp/frpc.toml
# 编辑配置文件(只需修改3处)
vim /etc/frp/frpc.toml需要修改的内容:
# 修改1:阿里云服务器公网IP
serverAddr = "8.138.xxx.xxx" # ← 改为你的阿里云IP
# 修改2:通信密钥(必须与阿里云一致)
auth.token = "你的安全密钥" # ← 改为你的密钥
# 修改3:虚拟机IP地址(如有)
localIP = "192.168.1.38" # ← 改为Halo VM实际IP
localIP = "192.168.1.3" # ← 改为NAS VM实际IP
2.3启动Frp客户端
# 下载并安装Frp(脚本已包含)
frp/frpc -c /etc/frp/frpc.toml
# 或设置为系统服务
systemctl start frpc
systemctl enable frpc步骤3:导入Grafana仪表板
平台:浏览器
- 访问 http://你的阿里云IP:3000
- 登录账号:admin,密码:你在步骤1.3设置的密码
- 左侧菜单 → Dashboards → Import
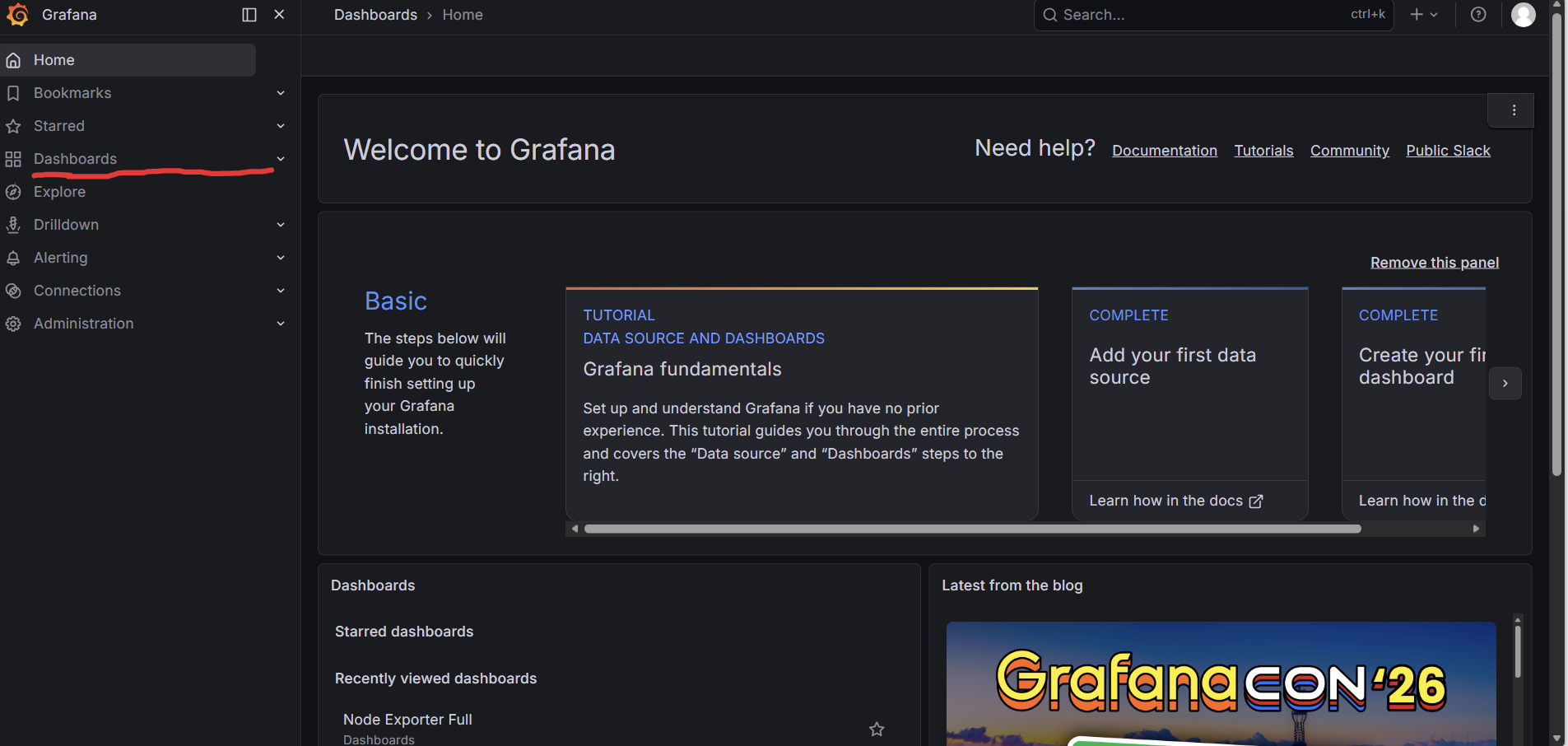
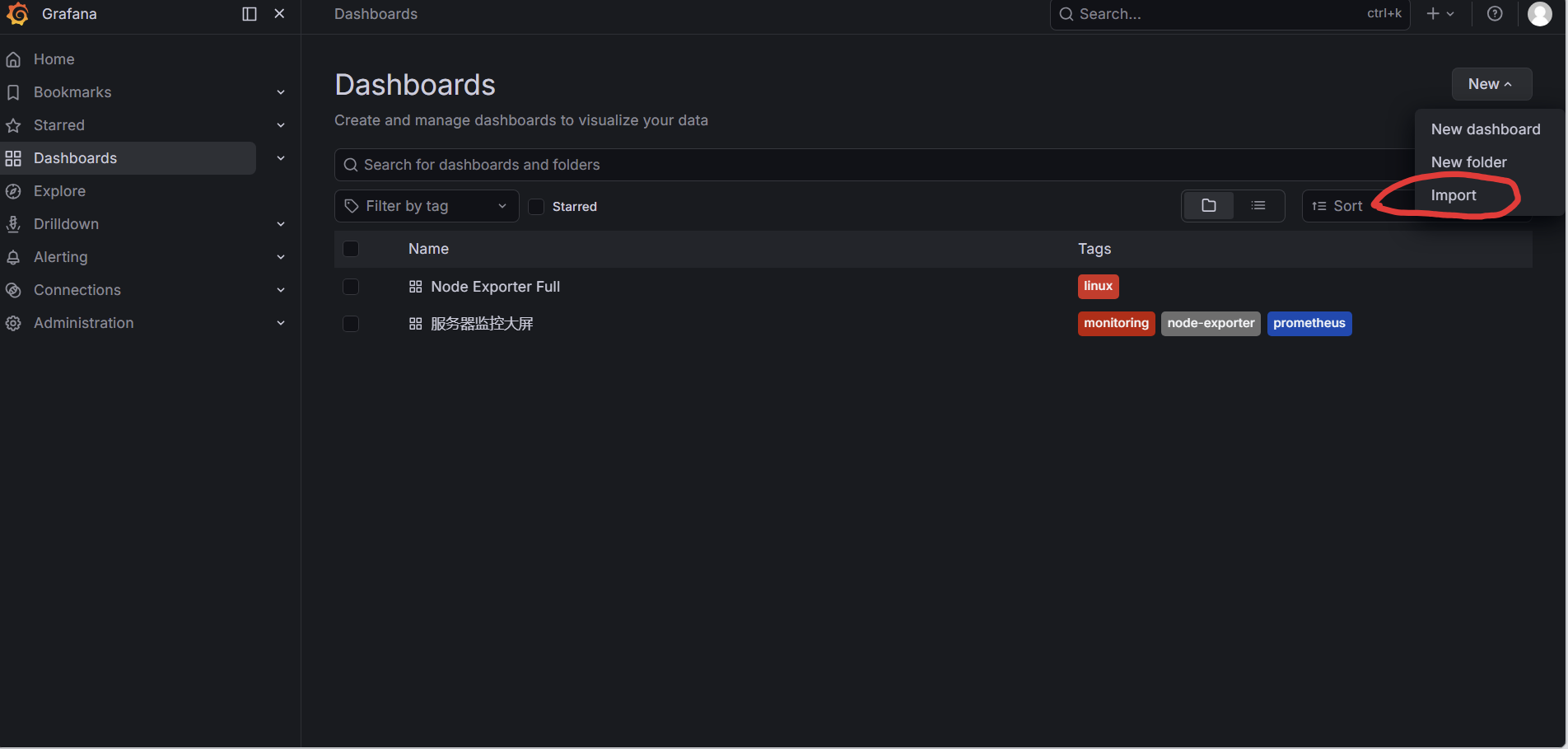
- 输入模板ID: 1860 → Load
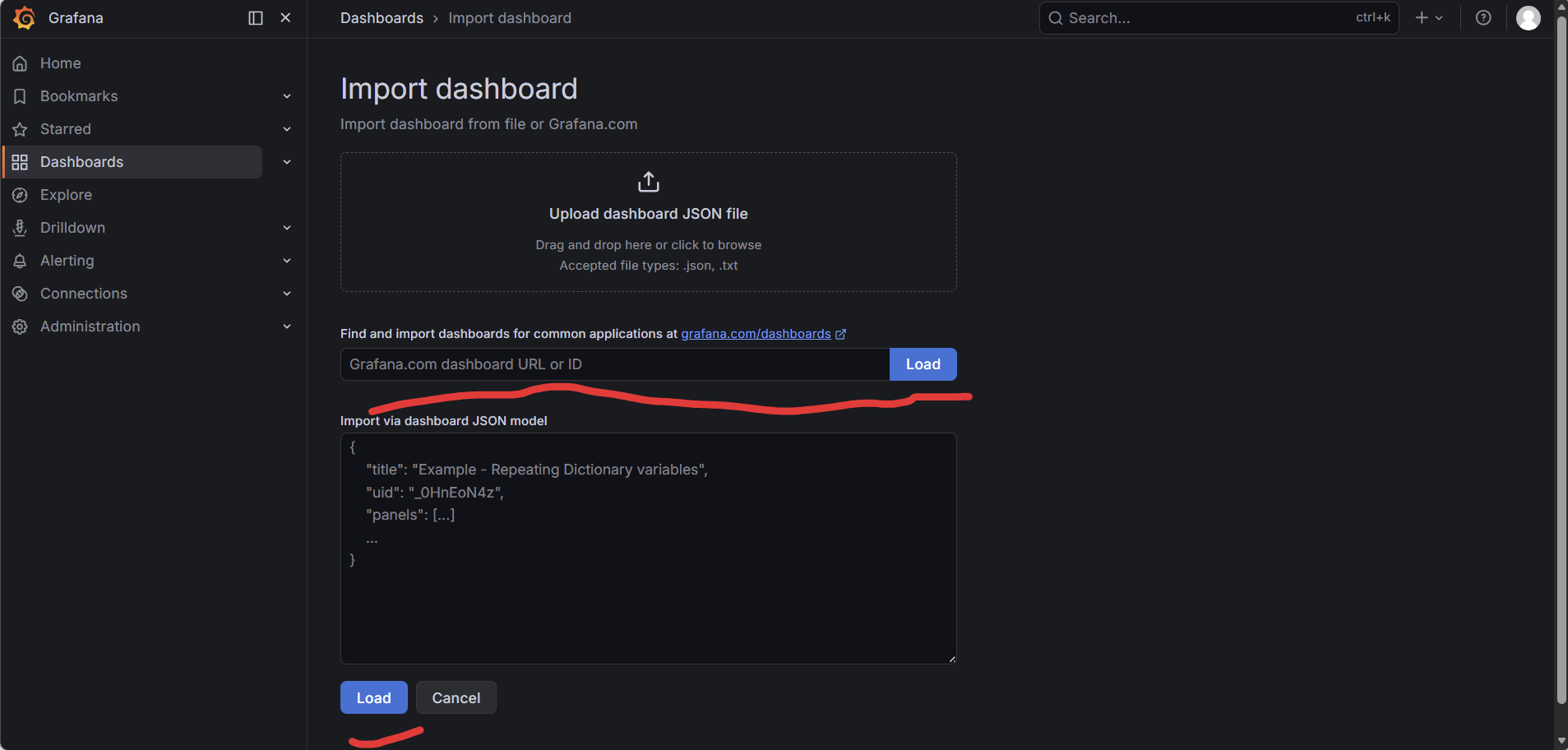
- 选择数据源 Prometheus → Import
三、配置修改清单
必须修改的配置项
一键部署自动处理
使用 deploy.sh 脚本时,只需输入以下信息:
- 阿里云公网IP
- Frp通信密钥
- Grafana管理员密码
- 钉钉/微信机器人token(可选)
四、快速验证
4.1 检查服务状态
# 阿里云服务器
docker compose ps
# 本地PVE服务器
systemctl status node_exporter
systemctl status frpc4.2 访问验证
- Grafana监控面板 : http://阿里云IP:3000
- Prometheus : http://阿里云IP:9090
- Frp管理面板 : http://阿里云IP:7500
4.3 监控效果
登录Grafana后,你应该能看到:
- aliyun-server(阿里云服务器)
- pve-host(PVE宿主机)
- halo-vm(Halo虚拟机)
- nas-vm(NAS虚拟机)
五、常见问题
5.1 服务无法启动
# 检查端口占用
netstat -tlnp | grep -E '3000|8006|9090|9093'
# 检查防火墙
systemctl status firewalld5.2 Frp连接失败
- 确认阿里云安全组已开放8006端口
- 确认frpc.toml中的serverAddr和token正确
- 检查网络连通性: telnet 阿里云IP 8006
5.3 监控数据不显示
- 确认Node Exporter已启动: curl http://localhost:9100/metrics
- 确认Frp隧道已建立:访问Frp管理面板查看连接状态